
K auzokide hurbilenak: berrikuspenen arteko aldeak
Orri berria: «'''K auzokide hurbilenen''' metodoa (ingelesez '''''k-nearest neighbors''''' edo '''K-NN''') datu-meatzaritzan sailkapen gainbegiraturako metodo bat da. Entr...» |
No edit summary |
||
| 82. lerroa: | 82. lerroa: | ||
== Erreferentziak == |
== Erreferentziak == |
||
{{erreferentzia_zerrenda}} |
|||
<references /><br /> |
|||
| ⚫ | |||
| ⚫ | |||
* [[Datu-meatzaritza|Datu meatzaritza]] |
* [[Datu-meatzaritza|Datu meatzaritza]] |
||
* [[Erabaki-zuhaitzen bidezko ikaskuntza|Erabakitze Zuhaitzak]] |
* [[Erabaki-zuhaitzen bidezko ikaskuntza|Erabakitze Zuhaitzak]] |
||
* [[Algoritmo |
* [[Algoritmo genetiko]]ak |
||
* [[Sailkatzaile Bayestarrak]] |
* [[Sailkatzaile Bayestarrak]] |
||
* [[Weka]] |
* [[Weka]] |
||
== Kanpo estekak == |
|||
<br /> |
|||
{{autoritate kontrola}} |
|||
[[Kategoria:Algoritmoak]] |
|||
[[Kategoria:Estatistika ez-parametrikoa]] |
|||
[[Kategoria:Ikasketa automatikoa]] |
|||
16:22, 23 abendua 2019ko berrikusketa
K auzokide hurbilenen metodoa (ingelesez k-nearest neighbors edo K-NN) datu-meatzaritzan sailkapen gainbegiraturako metodo bat da. Entrenamendurako kasuen artean, K auzokide hurbilenetan oinarritzen da kasu berrien sailkapena egiteko. Hurbileneko K auzokideen klase-aldagaiaren balioa aztertu eta sarrien agertzen den klasea esleitzen zaio kasu berriari.
K-NN algoritmoak ikasketa nagia edo alferra (lazy learning) egiten duela esaten da, ez duelako eredu bat induzitzen ikasketa-fasean; entrenamendurako datu-basetik eredu bat sortu beharrean, datu-base berarekin egiten da kasu berriaren klase-aldagaiaren iragarpena test-fasean.
Algoritmoaren bertsiorik sinpleenean K auzokide hurbilenen klaseei tratamendu bera ematen zaie, baina badira algoritmoaren aldaera desberdinak auzokideen artean bereizketa egiteko, kasu berrira duten distantziaren arabera garrantzia maila desberdina emateko, adibidez.
Algoritmoa

Entrenamendu fasean, datubasean ukango ditugun kasu guztiak gordeko ditugu, haien aldagai iragarle eta klasearekin.
Sailkatze fasean, erabiltzaileak K konstantea definitzen du eta sailkatu nahi duen kasu berria aurkezten du. Helburua kasu berri hori klase bat esleitzea denez, hurbilen dauden K elementuen artean gehien agertzen den klasea esleituko diogu, ondoko adibidean ikusten den bezala.
Bi elementuen artean “berdinketa” dagoen kasuan, klase bat eukeratzeko aterabide ezberdinak daude, besteak beste, hurbilenaren klasea esleitzea, edo batazabesteko distantzia txikiena duen klasea aukeratzea.
Gehienetan erabiltzen den distantzia, distantzia euklidearra da.
K aukeratu
K-ri baliorik egokiena esleitzea funtsean datuen mendean dago; gehienetan, k-ren balio handiek zarata txikiagotzen dute, baina antzeko klaseen arteko limiteak sortzen dituzte. K on bat erabilera optimizatuz aukera daiteke. Orokorrean, 3 eta 7 balioen artean aukeratzea gomendatzen da. Klasea entrenamenduaren adibidearen klaserik hurbilena izateko iragartzen den kasu berezia (k=1 denean) Nearest Neighbor Algorithm deitzen da, auzokide gertuenaren Algoritmoa.
Algoritmoaren aldaerak
Oinarrizko algoritmoari aldaera batzuk egiten ahal zaizkio. Horrela batzuetan emaitza hobeak lor daitezke, datubase batzuetan kasu batzuek ez daukatelako berme asko, edo distantzia kalkulatzeko modu ezberdinak erabiltzen ahal direlako, adibidez.
K-NN bermegabeak baztertuz
Aurretik hautatutako atalase baten bidez sailkatu nahi diren kasuek berme nahiko duten aukeratzen da, eta haien artean gehiengo absolutuaren bidez kasu berria sailkatzen da.
Adibidez, entrenamendu datubasean 2 klase ezberdinetan banatutako 10 kasu baldin badaude, atalasea 6koa jartzen da. Hori dela eta, kasu berri batek gutxienez sei bozka izan beharko ditu sailkatu ahal izateko.
K-NN aukeratutako auzokideen pisaketarekin
K-NN algoritmoaren aldaera honetan, kasu guztien arteko distantzia Euklidearrak kalkulatzen da.

non eta A kasuaren X eta Y parametroaren balioa den eta B kasuarenak.




Kasu berri bat sartzen denean, klase bat esleitzeko, K elementu hurbilena hartzen da eta haien klasearen arabera banatzen da. Ondoren, kasu bakoitzaren d distantziak kalkulatzen dira. eginez klase bakoitzeko kasuen pisuak kalkulatu ondoren, kasu berriari pisuen batura handiena duen klasea esleituko zaio.

K-NN batazbesteko distantziarekin
Kasu berritik K elementu hurbilenak kontutan hartuz, klase berdineko elementuen eta kasu berriaren arteko distantzien arteko batazbestekoak kalkulatzen dira, klase bakoitzeko. Ondoren, batazbesteko distantzia euklidear txikiena duen klasea esleituko zaio kasu berriari.
K-NN distantzia minimoarekin
Klase bakoitzari ordezkari bat esleitzen zaio eta kasu berrien sailkapena klaseen ordezkariekin 1-NN egitea izango litzateke, hau da, kasu berriari hurbilen duen ordezkariaren klasea esleituko zaio. Ordezkaria aukeratzeko, gehienetan barizentrutik (klase berdineko elementu guztien "zentroa") hurbilen dagoen kasua hautatzen da.
NN aldagaien pisaketarekin
Sailkatu beharreko x kasu berriaren eta sailkatutako kasuen arteko distantzia kalkulatzerakoan aldagaiei ez zaie pisu berdina emango. Aldagai bakoitzari dagokion garrantzia eman behar zaio. Honela kalkulatzen da kasu berriaren eta kasuaren arteko distantzia ponderatua:





eta pisuak aurretik daude finkaturik. Pisua kalkulatzeko modu bat aldagaiaren eta klase-aldagaiaren elkarrekiko informazioaren neurria erabiltzea da, . Neurria honela definitzen da:






Hasierako datubaseko datu kopuruaren murriztea
Hasierako datubaseko datu kopurua murrizteko bi metodo nagusi daude: Edizioa eta kondentsazioa. Edizio bat egitean, hasierako kasu guztietatik abiatuz batzuk kentzen zaizkio eta kondentsazio bat egitean aldiz, datubase huts batetik abiatuz beharrezkoak diren kasuak sartzen zaizkio.
Harten kondentsazioa
X entrenamenduko datubasea izanik eta U sortuko den datubase berria (hasieran entrenamenduko datubaseko lehen elementua sartuko da, hutsa egon ez dadin), iterazio bakoitzean, Xko elementuak korritu eta x elementu bat bilatu, non bere U-ko elementu hurbilenak klase ezberdin bat duen. x Xtik kendu eta U-ra gehitu eta errepikatu U ez aldatu arte.
Azpiko irudietan Harten kondentsazioaren emaitzak ikus daitezke. 1.irudian, hasierako datubasea ikus daiteke, non elementu bakoitzaren koloreak bere klasea adierazten duen. Bigarren irudian, 1.irudiko kasuek 1-NN sailkatzeilearekin daukaten predikzioak agertzen dira. 3.irudian, sailkapen berdina egiten da, 1-NN ordez 5-NN erabilita eta zonalde txuriek sailkatu gabeko kasuak erakusten dituzte (bi klaseen arteko berdinketa egon delako, adibidez). 4.irudian, Harten kondentsazioa egin ondorengo datubase berria agertzen da eta 5.ean, datubase berri horri aplikatutako 1-NNren emaitzak.
-
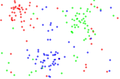 1.Irudia: Entrenamenduko datubasea
1.Irudia: Entrenamenduko datubasea -
 2.Irudia: Entrenamenduko datubasea 1NN aplikatuta
2.Irudia: Entrenamenduko datubasea 1NN aplikatuta -
 3.Irudia: Entrenamenduko datubasea 5NN aplikatuta
3.Irudia: Entrenamenduko datubasea 5NN aplikatuta -
 4.Irudia: Datubase murriztua
4.Irudia: Datubase murriztua -
 5.Irudia: Datubase murriztua 1NN aplikatuta
5.Irudia: Datubase murriztua 1NN aplikatuta





Ikus daiteke 2. eta 5.irudien artean ez dagoela ezberdintasun handirik, eta horri esker elementu berri bat sartzerakoan, bere klasea zein den azkarrago erabakitzen ahalko da, asmatze tasa asko apaldu gabe.
Wilsonen edizioa
Datubaseko elementu bakoitzari K-NN algoritmoa aplikatzen zaio (nahi dugun K hartuta), K elementu hurbilenetati sarrien agertzen den klasea esleitzen diogu. Hortik, esleitutako klasea eta klase erreala ezberdinak badira, kasua datubasetik ezabatzen da eta bestela gordetzen dugu.
Erreferentziak
Ikus, gainera
Kanpo estekak
| Autoritate kontrola |
|
|---|
 Datuak: Q1071612
Datuak: Q1071612