
Itzulpengintza automatiko
Itzulpen automatikoa (IA edo MT-Machine translation) testuen itzulpena automatikoki lortzeko ahalbidetzen duen teknologia da. Teknologia honek 1940tik hainbat hamarkadaz laguntza mugatua eskaini du, baina 2017z gero arrakasta handia lortu du, eta harrezkero erabilera askoz zabalagoa da.
Dena dela itzulpen automatikoaren emaitzak ez dira inoiz perfektuak izan, eta oraindik ere ez dira perfektuak. Emaitza horiek publikoki zabaldu nahi badira, guztiz beharrekoa da pertsona batek testua zuzentzea eta orraztea (post-edizioa).
Iturburu-hizkuntzako testu batetik abiatuta, helburu-hizkuntzako ahalik eta baliokideen den beste testu bat lortzea du helburu IAk, konputagailu bat erabilita. IA ez da nahastu behar konputagailuz lagundutako itzulpenarekin ez eta itzulpen-memorien erabilpen soilarekin.
Itzulpengintza automatikoa hizkuntza teknologiaren garapenean nabarmen lagundu duen diziplina da. Munduan badira zeregin nagusia hori duten hainbat elkarte zientifiko, aldizkari berezi, unibertsitate departamentu eta enpresa. Martin Kay adituaren esanetan:[1]
| « | Itzultzeko makinak lortzeko irrika horrek hizkuntzalaritza, filosofia, matematika edo informatika diziplinetako zenbait buruargiren arreta merezi izan du. Horretaz gain, itzulpen automatikoak jarraitzaile leial batzuengan erakarpen liluragarria pizten du. Zer dela eta lilura hori? | » |
Bitarteko mekanikoen bidez itzultzea bada erronka zientifiko bat. Baina itzulpen automatikoak horrenbesteko interesa piztearen benetako arrazoiak ez du sustrai zientifikorik, behar praktikoan du jatorria, informazioaren jarioan alegia. Itzulpengintzako lan errepikakorrenak[2] modu automatikoan egiten lortzea da lehen erronka. Azken helburua, agian, egunen batean adimen artifizialakren bidez pertsona batzuek lortzen duten maila profesionala makinekin lortzea da.
Historia[aldatu | aldatu iturburu kodea]
Makina itzultzaileak egiteko nahia ordenagailuak izan baino askoz ere lehenagokoa da. 1940ko hamarkadan ordenagailu bat eskura egon zenetik, itzulpengintza automatikoa berehala bilakatu zen informatikaren aplikaziorik arrakastatsuenetako batean. Ordutik hona, denbora egon da esperimentu anitz egiteko, txikiak eta handiak, bai eta instituzio zein industria mailako inbertsio handiak egitekoa ere. 1950eko hamarkadan itzultzaile automatiko bat sortzeko jarrera baikorra nagusi zen arren, 1966an argitaratutako ALPAC txostenak[3] jarrera eszeptikoa ekarri zuen eta, ikerketek Kanadan eta Europan jarraipena izan arren, Estatu Batuetan nabarmen egin zuen behera inbertsio nahiz ikerketak. Hala eta guztiz ere, 1980ko hamarkadan suspertu zen berriz, hainbat sistemen argitalpen eta teknika berrien agerpena zela medio. 1990eko hamarkadan, batez ere teknika estatistikoen hobekuntzarekin optimismorako joera areagotu zen eta gaur egun Interneten aurki daitezke sistema askoren inplementazioak zerbitzu modura erabiltzaileen eskura.
Suedia eta Finlandia Europako Batzordean sartu zirenean 1995ean, 60.000 arautze komunitario inguru itzuli behar izan ziren, "acquis communautaire" izenaz ezagutzen direnak. Hiru urte beranduago, 1999an, Bruselako legegizonen ahalegin nekaezinari esker, 20.000 arautzetan handitu zen kopurua. Ekialdeko Europako herriak EBan berehala sartzeak oso hizkuntza egoera delikatuan jartzen du Batzordea eta teknologia berrien aurrerakadak baino ezin lagun dezake egoera arintzen.
2014z geroztik neurona-sare handiak erabiltzen hasi ziren hitz-sekuentzia batek duen agertzeko probabilitatea aurreikusteko, eta normalean esaldi osoak ere modelatzen dira eredu integratu bakar batean. Itzulpen automatiko neuronal sakona aurrekoaren hedadura bat da. Biek erabiltzen dute neurona-sare handi bat baina itzulpen automatiko neuronal sakonak hainbat geruza prozesatzen ditu batera bakarka egin ordez. Alor honetan izan den garapena ikaragarri azkarra izan da, lorpenak eta hobekuntzak arin-arin gertatu dira urte gutxi-gutxi batzuetan. Horrela, Ikaskuntza sakona (deep learning) teknika Itzulpengintza automatikoan erabili zuen lehenengo argitalpen zientifikoa 2014ean agertu zen, egileak Bahdanau, Cho eta Bengio izan ziren. Handik urtebetera 2015ean bazegoen neurona-sistema bat itzulpen automatikozko txapelketa batean (OpenMT’15). Eta hurrengo urtean txapeldunen %90a sistema neuronalak izan ziren. 2015eko aurrerapena arretan oinarritutako sistemak ("attenttion based NMT") erabiltzea izan zen. 2017an hobekuntza gehigarriak lortu ziren neurona-sareetan Transformer arkitektura erabiltzearen ondorioz. Urte bat geroago euskara ere arrakastaz erabiltzen zuen sistema bat zegoen, eta beste urte batean, 2019an, euskararako zeuden neurona-sistemak bost ziren.
Zailtasunak[aldatu | aldatu iturburu kodea]

Gizaki baten mailara iritsiko den IA lortzea kontu zaila da, ez baita nolanahikoa makina bati erakustea gizaki batek izan dezakeen ezagutza (testuingurua) ez eta erabakiak hartzeko gaitasuna (nola ebatzi anbiguotasunak?).
Gauza jakina da hizkuntza guztiek ez dituztela ezaugarri berak eta sintaxiaren ordenari dagokionez egitura ezberdinak erabiltzen direla. Ez baita berdina antzeko egitura sintaktikoak dituzten hizkuntzen arteko IA edo egitura sintaktiko erabat ezberdinak dituzten hizkuntzen artekoa. Lehenengoak prozesamendu eta baliabide gutxiago eskatzen ditu eta emaitzak ere hobeak dira bigarrenean baino. Bigarrenak, beraz, aparteko prozesaketa eskatuko du esaldi bateko elementuen ordena ebazterako orduan.
IAri ekiteko aukeratutako estrategiaren arabera, gainera, beharrezko baliabideak neurri ezberdinetakoak izan daitezke. Corpusetan oinarritutako IAren kasurako, adibidez, ezinbestekoa da corpus eleaniztun handiak izatea, sistemak bertatik ikasteko aukera izan dezan eta munduarekiko ikuspegi zabalagoa izan dezan.
Esan bezala, anbiguotasunen gaineko erabakiak hartzea kontu zaila izan daiteke eta, ondorioz, helburu orokorreko IA egin ordez badira domeinu konkretuetan espezializatzen diren sistemak, sarrera mugatuagoa izanik, anbiguotasunerako aukerak ere murrizten baitira eta horrek eragin zuzena baitu lortutako emaitzetan.
Ikus daitekeenez, hainbat dira gainditu beharreko trabak kalitatezko IA lortu nahi bada, horregatik, IAren erronkak eta egun arte egindako bidea ikusita, beti dago eszeptikotasuna adieraziko duenik[4]. Joseph Bonet-ek horrela zioen 2006an:
| « | IA etorkizun handiko teknologia da. 30 urte baino gehiago gabiltza etorkizun handia duela esaten. Baina agindutakoa ez da betetzen. | » |
Neurona-sareen ekarriarekin 2017z geroztik izugarrizko hobekuntza nabaritu izan da itzultzaile automatikoetan.
Estrategiak[aldatu | aldatu iturburu kodea]
Garapena[aldatu | aldatu iturburu kodea]
Itzulpen automatikoari aplikaturiko metodoak hiru talde handitan bana ditzakegu:
- Erregeletan oinarritutako IA (1940)
- Corpusetan oinarrituriko IA (2000)
- Itzulpen automatiko neuronala (2017)
Ikuspuntu teorikotik erabat kontrajarririk dauden hurbilpenak dira, diseinuaren aldetik sistema oso ezberdinak baitira. Arauetan oinarrituriko sistemek euren kontzepzio teorikoan, Hizkuntzalaritza Sortzailean eta adimen artifizialean izandako aurrerapenen eragina izan dute, batez ere, 1970eko hamarkadatik aurrera.
Analogietan oinarrituriko sistemak 1990eko hamarkadan agertu ziren eta hurbilpen estatistikoen metodoak aplikatzen dituzte aldez aurretik itzulita dauden testu zatien gainean. Ele egitea eta Corpus Hizkuntzalaritza aztertzeko sistemetan erabilitako tekniken antzekoak aplikatzen dituzte.
Paradigma neuronalaren ekarriarekin 2017z geroztik izugarrizko hobekuntza nabaritu zen itzultzaile automatikoetan. Hasieran hizkuntza nagusienen arteko itzulpenetan ikusi zen arrakasta, baina 2018z gero euskara bezalako hizkuntzetan ere erabili da arrakastarekin.
1990eko hamarkadara arte ikerlarien artean izan den premisarik indartsuenetako bat, itzulpena funtsean parekotasun semantikoaren arazo gisa hartzea izan da. Premisa horren oinarria Leibnizen garairaino heldu eta Frege eta Montaguek, semantika garaikidearen aitak, hartu zuten ustean dago, alegia, munduko hizkuntza guztiek azpiegitura logiko bera dutela. Horrela izatekotan, azpiegitura hori asmatu eta formalizatzeko gai bagina itzulpenaren arazoa konponduta legoke.
Ideia horrekin, ikertzaileak parekotasun kontzeptualaren arazoa konpontzen saiatu dira, bai adierazpen neutro eta komunen bitartez –hizkuntzen arteko edo interlingua teknika–, bai hizkuntza bikoteen artean tarteko adierazpenak proiektatuz –transferentzia teknika–. Semantikaren tratamendu konputazionalerako gehien erabiltzen diren ereduen artean azpimarratzekoak dira honako hauek: sare semantikoak, lehentasun semantikoak, kasu eta balentzia gramatikak, adierazpen kontzeptualak, transferentzia lexikoa, semantika lexikoa eta desanbiguazio lexikoa.
Uste teoriko hori seguruenik itzultzaileentzat itzulpen sistema erabilgarrien garapena gehien kaltetu duen alderdia da eta duela gutxi arte ikertzaile gutxi batzuk (Melby edo Kay) ausartu dira kritikak egiten. Melby izan da hizkuntzen arteko unibertsaltasun kontzeptualaren hipotesia era argi batean zalantzan jarri zuen lehena.
Itzultzaile profesionalek zalantzan jarri izan dute ideia horren baliagarritasuna Interneteko foro ezagunetan islatzen den legez. Horrez gain, itzulpengintzaren esparruan semantikoa bezain garrantzitsuak diren parekotasun mailak deskribatzen dituzten azterketak berriak dira. Nord-ek, itzulpen parekotasunaren azterketan egilerik nabarmenena den emakumeak, bi dimentsio gehiago proposatzen ditu, parekotasun estatistikoa eta parekotasun pragmatikoa. Bestalde, Hatim eta Mason-ek, itzulpena soilik linguistikoa baino, batez ere zentzu pragmatikodun kontutzat hartzearen garrantzia azpimarratzen dute eta parekotasun abstraktuagoa duen maila proposatzen dute sinbolo sozial eta kulturalen eremuan, hots, semiotikarenean.
Metodoak[aldatu | aldatu iturburu kodea]
Itzulpen automatikoa lortzeko estrategiari begiratzea da sailkapen klasikoena. Hiru multzo nagusi nabarmen daitezke: neurona-sarretan oinarritutako metodoak, erregeletan oinarritutako metodoak eta corpusetan oinarritutakoak.
Itzulpen automatiko neuronala[aldatu | aldatu iturburu kodea]
Neurona-sareen ekarriarekin 2017z geroztik izugarrizko hobekuntza nabaritu zen hizkuntza nagusienen arteko itzultzaile automatikoetan.
Erregeletan oinarritutako IA[aldatu | aldatu iturburu kodea]
Erregeletan oinarritutako IAren barruan itzulpen zuzena, transferentziazko edo interlingua bidezko metodoak aurki ditzakegu.

Corpusetan oinarritutako IA[aldatu | aldatu iturburu kodea]
Erabilerak[aldatu | aldatu iturburu kodea]
Erabileraren aldetik bi atal nagusi bereizten dira, asimilazioa (assimilation) eta zabalkundea (dissemination).
- Asimilazioa: sistema azkarrak dira baina itzulpenak kalitate txarrekoak. Testuaren ideia nagusi edo muina harrapatzeko balio dute.
- Zabalkundea: emaitzak kalitate onekoak dira, baina ez inon argitaratzeko modukoak. Hau egin nahi bada, ezinbestekoa da posteditatzea. Askotan eremu zehatz batera (ezagutza jakin batera, alegia) mugatutako sistemak dira, horrela sarrerako hizkuntzaren nolakotasuna mugatzen baita eta anbiguotasunak neurri batean saihesten baitira
Euskararako itzultzaile neuronalak[aldatu | aldatu iturburu kodea]
Paradigma neuronalaren ekarriarekin 2017z geroztik izugarrizko hobekuntza nabaritu zen hizkuntza nagusienen arteko itzultzaile automatikoetan. Geroxeago, eta arin, euskal munduko ikerkuntza komunitatea gai izan zen euskaratik eta euskararako itzultzaile neuronalak mundu mailako artearen egoeraren pare jartzeko.
2015ean hasi zen euskararako itzulpen neuronala aztertzen TADEEP proiektuan.[5] Ordurako Deepl itzultzaileak kalitatezko emaitzak ematen zituen 10 hizkuntzatan baina euskara ez zegoen horien artean.[6] Bi urte geroago lehenengo emaitza bikainak lortuta, 2017an lehen demoa publikoki eskura zegoen. 2017an bertan, hainbat agente (Ixa Taldea, Elhuyar, Vicomtech, Ametzagaña, Mondragon Lingua...) batera, MODELA izeneko proiektua abiatu zen.[6][7] Beste urtebeteko epean, 2018an MODELA itzultzailea plazaratu zen, Interneten publiko orokorrerako euskarazko itzulpen neuronala eskaintzen zuen lehen zerbitzua.
Abiada bizian mugitzen zen arlo honetan, geroago gutxienez beste hiru itzultzaile neuronal gehiago plazaratu ziren. Horien arteko diferentzia nagusia itzultzaile bakoitzak erabiltzen duen corpusa da (corpus = milioika esaldi bi hizkuntzatan), baita itzultzeko zerbitzuan onartzen duten hitz-kopuru maximoa ere (konputagailu ahaltsu eta garestiak erabili behar dira horretan). Hauek ziren 2020ko hasieran eskaintzen ziren euskararako itzultzaile neuronalak:
- Eusko Jaurlaritzaren Itzultzaile neuronala: itzulpen neuronalaren teknologia erabilita, corpus-oinarria Eusko Jaurlaritzako itzulpen-memoriak erabili ziren IVAP-HAEEk 20 urtetan bildutakoa 10 milioi "esaldi" baino gehiago..[8]
- batua.eus: Vicomtech-ek MODELA sisteman hobekuntzak egin zituen (RNN teknologiatik Transformer teknologiara pasa ziren) eta corpusa handitu zuten.[9][10]
- elia.eus (hasieran Itzultzailea.eus izena zuen, 2021era arte): Elhuyarrek ere antzeko hobekuntzak egin zituen bere aldetik. Eta itzulpenak egiteko hizkuntza berriak gehitu zituen (ingelesa, frantsesa, espainiera, galegoa, eta katalana)[11][12] 2019ko bertsioak itzultzailea.eus izena zuen, eta 2020ko urtean izugarrizko arrakasta lortu zuen: 1.776.767 bisita jaso eta 12.180.660 itzulpen-eskaera bideratu zituen.[13]
- Translate Google: Googleren Translate zerbitzuak hobekuntzak lortu zituen eredu neuronala erabilita.[14]
-
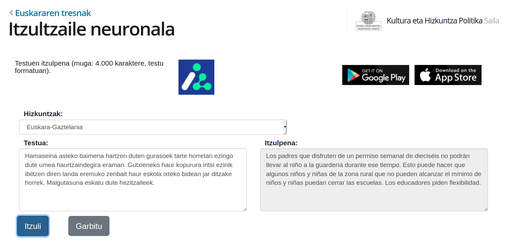 Jaurlaritzaren itzutzaile neuronala
Jaurlaritzaren itzutzaile neuronala -
 Batua.eus
Batua.eus -




Itzultzaile automatiko batzuk[aldatu | aldatu iturburu kodea]
Euskarara edo euskaratik itzulpenak egiten dituzten itzultzaile automatikoak gero eta gehiago dira,[14] horra zerrenda bat:
- Batua.eus
- elia.eus (lehen itzultzailea.eus): itzulpenak egiteko hizkuntza berriak gehitu zituen (ingelesa, frantsesa, espainiera, galegoa, eta katalana)[11]
- lingua.eus: MondragonLingua.[15]
- Eusko Jaurlaritza: Itzultzaile automatikoak; Itzultzaile neuronala + Itzultzaile gramatikala
- Eusko Jaurlaritza: Itzultzaile neuronala ES > EU, EU > ES[15].
- Eusko Jaurlaritza: Itzultzaile gramatikala.[16][17] ES > EU, EU > ES, EU > EN, EN > EU.
- Lanbide heziketako hiztegia (+ ikus eskuinean, "Itzulpen laguntzak").
- Content Translation: Wikipediako artikuluak errazago itzultzeko tresna (estekak, wikiestekak, formatoak, erreferentziak...). Hainbat hizkuntzen artean erabil daiteke eta euskara dago horien artean.[16][17][18]
- Wikimedia Fundationek eskaintzen duen itzulpengintza automatiko zerbitzua
- Google Translate
- Modela[18]. ES > EU, EU > ES.
- Matxin[19][20]. ES > EU.
- Apertium[21]
- Opentrad. Hainbat hizkuntza aukeran: CA, EN, ES, EU, FR, GL, PT..
Euskara ez den beste hizkuntzetarako itzulpenak egiten dituzten itzultzaile automatikoak ere gero eta gehiago dira, horra zerrenda bat:
- DEEPL translator Zortzi hizkuntza nagusien artean kalitatezko itzulpen neuronala 2017tik
- Google Translate
- Apertium[21]
- Opentrad. Hainbat hizkuntza aukeran: CA, EN, ES, EU, FR, GL, PT.
- Content Translation: Wikipediako artikuluak errazago itzultzeko tresna (estekak, wikiestekak, formatoak, erreferentziak...). Hainbat hizkuntzen artean erabil daiteke eta euskara dago horien artean.
- Wikimedia Fundationek eskaintzen duen itzulpengintza automatiko zerbitzua
Erreferentziak[aldatu | aldatu iturburu kodea]
- ↑ (Ingelesez) An introduction to machine translation, hitzaurrea by W.John Hutchins and Harold L. Somers
- ↑ «Itzulpen automatikoa (Sareko Euskal Gramatika)» www.ehu.eus (Noiz kontsultatua: 2019-02-24).
- ↑ (Ingelesez) ALPAC. 1966. Language and machines: computers in translation and linguistics. A report by the Automatic Language Processing Advisory Committee. Washington, DC, National Academy of Sciences.
- ↑ (Ingelesez) "Present and future of Machine Translation in the Directorate-General fro translation of the European Commission". In Proceedings of TC-START Workshop on Speech-to-Speech Translation. 2006, Barcelona. Josep Bonet.
- ↑ «Welcome to TAdeep (MINECO-FEDER project) | TAdeep» ixa2.si.ehu.es (Noiz kontsultatua: 2020-01-28).
- ↑ a b Alegria, Iñaki. (2018-09-11). «Itzulpen automatiko neuronalaren aurrerapenak eskura» Sarean .eus (Noiz kontsultatua: 2020-07-13).
- ↑ «MODELA» modela.ametza.com (Noiz kontsultatua: 2020-01-28).
- ↑ Eusko Jaurlaritza. (2019). «Euskara-Gaztelania itzultzaile automatiko neuronala» www.euskadi.eus (Noiz kontsultatua: 2020-01-28).
- ↑ «BATUA.eus - Euskarazko itzultzailea» www.batua.eus (Noiz kontsultatua: 2020-01-28).
- ↑ Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N; Kaiser, Łukasz; Polosukhin, Illia. (2017). Guyon, I. ed. «Attention is All you Need» Advances in Neural Information Processing Systems 30 (Curran Associates, Inc.): 5998–6008. (Noiz kontsultatua: 2020-01-28).
- ↑ a b «Itzultzailea» Itzultzailea (Noiz kontsultatua: 2020-01-28).
- ↑ «Elhuyarren itzultzaile automatiko eleaniztuna, doan ordenagailu eta mugikorretarako» Elhuyar (Noiz kontsultatua: 2020-07-07).
- ↑ «Elhuyarren itzultzaileak izen berria du: Elia» GAUR8 2021-03-22 (Noiz kontsultatua: 2021-03-23).
- ↑ «Google Translate» translate.google.com (Noiz kontsultatua: 2020-01-28).
- ↑ «MondragonLinguaren Itzultzailea - Itzultzailea» lingua.eus (Noiz kontsultatua: 2021-10-11).
- ↑ «Wikipedia-Wikimedia editatoia 2020. :: ikasi :: Udako Euskal Unibertsitatea» www.ueu.eus (Noiz kontsultatua: 2020-07-13).
- ↑ Wikiproiektu:UEU ikastaroa 2020. 2020-07-13 (Noiz kontsultatua: 2020-07-13).
- ↑ «Itzulpen automatikoa wikilariak laguntzeko — Unibertsitatea.Net» www.unibertsitatea.net (Noiz kontsultatua: 2020-07-13).
Bibliografia[aldatu | aldatu iturburu kodea]
- (Ingelesez) Doug Arnold, Balkan, L., Meijer, S., Humphreys, R.L. Sadler, L. 1993. Machine Translation: An Introductory Guide.
- (Ingelesez) Paul Bennett. 1994. Translation Units in Human and Machine. Babel 40:12-20.
- (Ingelesez) Bert Esselink. 1998. A practical guide to software localization. John Benjamins.
- (Ingelesez) Ethnologue. 2001. Languages of the World.
- (Ingelesez) W. John Hutchins & Harold L. Somers. 1992. An Introduction to Machine Translation. Academic Press.
- (Ingelesez) W.John Hutchins. 2001. Machine translation over fifty years. Histoire, Epistemologie, Langage. XXII-1:7-31.
- (Ingelesez) Martin Kay. 1997. The Proper Place of Men and Machines in Language Translation. Machine Translation 13:3-23.
- (Ingelesez) Alan K. Melby. 1995. The Possibility of Language. A discussion of the nature of language with implications for human and machine translation. John Benjamins.
- (Ingelesez) Sergei Nirenburg. 1987. Machine Translation: Theoretical and Methodological Issues. Cambridge University Press.
- (Ingelesez) Johnatan Slocum. 1988. Machine Translation Systems. Cambridge University Press.
- (Ingelesez) Machine Translation book (D.J.Arnold eta bestek (1994) egindako liburua).
- (Ingelesez) Machine Translation Archive artikulu teknikoen artxiboa.
- (Ingelesez) John Hutchins-en lanak.
Ikus, gainera[aldatu | aldatu iturburu kodea]
- Itzulpengintza automatiko neuronal
- Itzulpengintza automatikoaren historia.
- Adibideetan oinarritutako itzulpengintza automatikoa.
- Erregeletan oinarritutako itzulpen automatikoa.
- Estatistiketan oinarritutako itzulpen automatikoa.
Kanpo estekak[aldatu | aldatu iturburu kodea]
 Datuak: Q79798
Datuak: Q79798 Multimedia: Machine translation / Q79798
Multimedia: Machine translation / Q79798