
Morfologia konputazional

Morfologia konputazionala giza lengoaietako hitzen osaketa eta egitura ikertu eta aztertzeko informatikaz baliatzen den arloa da.[2][3] Horretarako, lengoaia naturaleko hitzak modu logikoan modelatzen saiatzen da, ikuspegi konputazional batetik beti ere. Modelaketa hori ez da soilik hizkuntzalaritzarena den morfologia atalean burutzen, morfologia konputazionalean hizkuntzalari, informatikari, psikologo eta logikako adituek ere parte hartu dezaketelarik.
Morfologiaren ikuspuntutik hitzen oinarrizko osagaiak morfemak dira. adibidez: etxera = etxe+ra, garbitzailearekin = garbi+tzaile+ arekin. Horretan bi motako morfemak bereizten dira: batetik lemak edo morfema askeak, adibidez: etxe, joan, lirain...; eta bestetik, hizkiak edo afixuak (aurrizki, artizki eta atzizkiak), adibidez: aurre-, -arekin, -tzaile... Atzikien artean bereizten dira deklinabide-atzizkiak (-arekin, -tik, -etaraino...) eta eratorpen-atzizkiak (-tzaile, -gailu...).
Hizkuntza guztiek ez dute berdin jokatzen morfologia mailan, hitzak osatzeko moduak asko aldatzen daitezke hizkuntza batetik beste batera. Euskarazko hitzen morfologia oso aberatsa dela esan daiteke inguruko hizkuntzekin konparatuz gero. Hizkuntzaren prozesamenduan euskara landu ahal izateko funtsezkoa izan da morfologia, baina hori ez da gertatu teknologia horretan alde handiz aitzindaria izan den ingeles hizkuntza aztertzerakoan. Europa mailan finlandiera eta hungariera ere oso aberatsak dira morfologikoki, eta hizkuntza horiek lantzeko tresnak erabilgarri izan dira euskara lantzeko ere.[4][5][6]

40 urtetan euskararako egindako lan konputazional desberdinak bi eremu hauen arabera eraiki dira: batetik teknologiaren bilakaera eta izaeran, eta bestetik, hortik eratorritako aplikazioetan. Teknologiari dagokionez, ezagutza linguistikoan oinarritutako ereduak ohikoak eta nagusi (izan) dira morfologian, baina hurbilpen estatistikoan, eta, batez ere, ikasketa sakonean oinarritutakoak ugalduz joan dira azken urteotan, horietako asko datuak eta gramatikak eskuragarri ez dituzten hizkuntzetarako (edo dialektoetarako). Aplikazioei dagokienez, ezagunena eta erabiliena zuzentzaile ortografikoa da, baina irakaskuntzarekin, itzulpen automatikoarekin edo bertsogintzarekin lotutakoak ere aipagarriak dira.[2]
Euskararen azterketa morfo-konputazionala[aldatu | aldatu iturburu kodea]

1988 urtean Ixa taldea sortu zenean, erabaki estrategiko garrantzitsua izan zen euskararen morfologiaren tratamenduari lehentasuna ematea. Lanari ekin ziotenean gazteak eta berriak ziren arloan, orduko konputagailuak oso oinarrizkoak ziren, baliabideak urri, nazioarteko zientzia kontsultatzeko aukerak, zailak; baina bazuten urteekin baloratzen ikasi zuten altxor bat: euskara batuaren definizio finkatu samarra, eta bere barruan haientzat ezinbestekoak ziren bi osagai: lexikoa eta morfologia. Horrez gain, arauari jarraitzen zioten testuak eta lankidetzarako prest zegoen komunitate zabal bat. Hori gabe nekez lortuko zuten hurrengo urteetan lortu zutena, Xuxen zuzentzaile ortografikoa edo artearen egoeran dagoen itzultzaile automatikoa, esaterako.
Ixa taldeak, sorreratik, estrategia bat definitu zuen euskararen prozesaketa automatikoa modu iraunkorrean garatu ahal izateko,[9] eta estrategia horren barruan lexikoak eta morfologiak erabateko lehentasuna zuten. Estrategiaren puntu nagusiak hauek ziren:
- Hasieran oinarrizko baliabide eta tresna sendoak sortu behar dira.
- Lexiko-morfologia-sintaxia-semantika progresioa aplikatu behar da.
- Formatu estandarrak erabili behar dira.
- Ahal den guztietan saiatu behar da software librea erabiltzen eta sortzen.
Euskal morfologiaren modelizazioa[aldatu | aldatu iturburu kodea]
Horrela, bada, lexikoari eta morfologiari ekin zioten. Euskara batuaren lexikoa eta gramatika aztertuta, lexikoaren datu-basea osatzera jo zuten eta morfologia modelizatzeko formalismo baten bila hasi ziren, euskal morfologia konputazionalki landu ahal izateko.
Euskara hizkuntza eranskaria da[aldatu | aldatu iturburu kodea]
Eredu baten bila, arloko antzeko lanak bilatzen hasi eta ageriko kontu batekin egin zuten topo, alegia, ikerketa gehiena ingeleserako egiten zela eta ingeleserako aplikatzen ziren tresnak ez zirela egokiak euskara bezalako hizkuntza eranskari bati aplikatzeko. Eranskaria izanda, ingelesak baino morfologia aberatsagoa du euskarak.[10] Hizkuntzen tipologia morfologikoaren inguruko sailkapenetik dator eranskari terminoa, morfemen fusioaren edo uztartze mailako irizpidea aplikatuta. Horrela, hizkuntza eranskarietako hitzen morfemek esanahi bakarra dute, bakoitzak bat, eta ez dago fusiorik, latinean topatzen ahal dugun moduan, non morfo bakarrak morfema bati baino gehiagori egiten baitio erreferentzia. Espero izatekoa da, beraz, hizkuntza eranskarietan morfema kopuru altuagoa hitzeko, beste hizkuntza malgukariekin edo flexiboekin konparatuta. Are gehiago, hizkuntzen sailkapen morfologikorako tipologian erabiltzen den beste irizpidea aplikatuta, hots, sintesiarena. Irizpide honi jarraituz, kontuan hartzen da hitz batek dituen morfema kopurua. Sailkapen honetan daude hizkuntza analitikoak, isolatzaileak ere deituak, morfema bakarrekoak, eta beste muturrean, polisintetikoak, hiru morfema baino gehiago dituztenak hitzeko. Tartean eranskariak daude. Hizkuntza bakartzaileen eredurik argiena txinera da eta ingelesa ere bai, neurri handi batean. Hala ere, sailkapen honetako kategoria hauek guztiak idealak direla, hizkuntza-tipologia puruei dagozkielako. Hizkuntzak, ordea, ez dira tipologikoki puruak, baina hurbiltzen dira ideal horietara. Hori dio, adibidez, Manterolak euskararen eranskaritasunari buruz, nahiz eta ikuspegi diakronikoa izan.[11]
Euskararen morfologia aberatsa[aldatu | aldatu iturburu kodea]

Gauzak horrela, behin informazio lexiko eta morfologikoa ordenagailuan txertatua izan zutenean erraza izan zitzaien frogatzea euskal morfologiaren aberastasuna. Eta frogatuta geratu zen euskararen aberastasun hori forma flexionatuak sortzeko duen ahalmen izugarrian dagoela. Aberastasun horren adibideak dira honako hauek:[12] Hizkuntzalaritza Konputazionala 38 Gatozen orain euskarara edo edozein hizkuntza eranskaritara. Mendi adibidearekin jarraituz, mugatu/mugagabe marka erantsi behar diogu, artikulua alegia —mugatuetan—, eta horietako bakoitzari aldian aldiko kasua. Are gehiago, kasu bat baino gehiago har dezake genitiboak, esaterako, eta berriro mugatasuna eta kasua hartzeko prest egongo da. Horrela ad infinitum irits gaitezke teorian, praktikan birritan baino gehiago aplikatzea normala ez bada ere. Eta adjektiboei hiru gradu-marka erantsi behar diegu, horiek ere mugatasuna eta kasua har dezakete-eta, forma neutroaz gain.
- Izen-sarrera batetik abiatuz 135 forma flexionatu lor daitezke gutxienez. Horietako 77 determinazioa, numeroa eta deklinabide-kasua konbinatuz lortutako forma ez-emankorrak diren bitartean, gainerako beste 58ak forma emankorrak dira bi genitiboetako batez bukatutako forma sinple edo deklinatuak baitira. Genitiboen atzetik teorikoki hasierako emankortasun-ahalmen guztia dago, genitiboaren atzetik flexiorik agertzean elipsi bat dago eta. Elipsi bat baino gehiago posible izanik, atzizki-hartzea errekurtsiboa izan liteke, maila teorikoan behintzat (adibidez; etxekoarenarekin = etxeko+elipsi+aren+elipsi+arekin), eta ondorioz, emankortasun-ahalmena infinitua litzateke. Izan ere, elipsi bat baino gehiago agertzea ohizkoa ez bada ere oso arraro ez diren forma batzuek bi elipsi edo gehiago dute. Aurrekoaren ondorioz eta bi elipsi kontuan hartuz izen bati dagozkion forma flexionatuak honako hauek lirateke : 77 + 58 (77 + 58 (77 + 58)) = 458.683.[13]
- Izen bakoitzeko horiek baino gehiago ezagutzeko eta sortzeko gai izan behar du euskararako prozesadore morfologiko batek.[12][14]
- Emankortasun morfologiko hori adjektiboen kasuan are handiagoa da, gradu-flexioa dela-eta (zuri, zuriago, zurien...) lau aldiz handiagoa baita.
| n | Kasua | Mugagabea | Mug. sing. | Mug. plur. | Plur. hurbila |
|---|---|---|---|---|---|
| 1 | Absolutiboa | mendi | mendia | mendiak | mendiok |
| 2 | Partitiboa | mendirik | |||
| 3 | Ergatiboa | mendik | mendiak | mendiek | mendiok |
| 4 | Datiboa | mendiri | mendiari | mendiei | mendioi |
| 5 | Inesiboa | menditan | mendian | mendietan | mendiotan |
| 6 | Leku-genitiboa | menditako | mendiko | mendietako | mendiotako |
| 7 | Adlatiboa | menditara(t) | mendira(t) | mendietara(t) | mendiotara(t) |
| 8 | Hurbiltze-adlatiboa | menditarantz | mendirantz | mendietarantz | mendiotarantz |
| 9 | Muga-adlatiboa | menditaraino | mendiraino | mendietaraino | mendiotaraino |
| 10 | Ablatiboa | menditatik, menditarik | menditik | mendietatik, mendietarik | mendiotatik, mendiotarik |
| 11 | Genitiboa | mendiren | mendiaren | mendien | mendion |
| 12 | Soziatiboa | mendirekin | mendiarekin | mendiekin | mendiokin |
| 13 | Instrumentala | mendiz | mendiaz | mendiez | mendioz |
| 14 | Motibatiboa | mendi(ren)gatik | mendia(ren)gatik | mendiengatik | mendiongatik, |
| 15 | Destinatiboa | ||||
| Gen. (gutxi erabilia) | mendirentzat | mendiarentzat | mendientzat | mendiontzat, | |
| Ines. (gutxi erabilia) | menditako | mendiko | mendietako | mendiotako | |
| Adlat. (gutxi erabilia) | menditarako | mendirako | mendietarako | mendiotarako | |
| 16 | Banatzailea | mendiko | |||
| 17 | Prolatiboa | menditzat, menditako |
Bi mailatako formalismoa egokia zen euskararentzat[aldatu | aldatu iturburu kodea]
Egoera honen aurrean 1990ean-edo ez zen erraza izan aurkitzea morfologia konplexu bati aurre egiteko gaitasuna izango lukeen formalismo bat.

Zorionez, Lauri Karttunen eta Kimmo Koskenniemmi finlandiarrek proposamen interesgarriak eginak zituzten, eta bigarrengoaren tesian oinarritu ziren ikerlari euskaldunak deskribapen morfologikoaren osagaiak modelizatzeko eta prozesatzeko programak idazteko orduan.
Argitaratu zuten lehen artikuluan,[16] Elhuyar aldizkari historikoan, formalismo horren ezaugarri nagusiak azaltzen ziren:
- Eredu orokorra da, edozein hizkuntzari aplika dakiokeena.
- Ezagutza linguistikoa eta algoritmoa bereizi egiten ditu eta, ondorioz, programa berak edozein hizkuntzatarako balio dezake.
- Baliagarria da hitzen analisi morfologikorako zein hitz-sorkuntzarako.
- Analizatu edo sortuko den hitzaren azaleko maila eta hiztegiko sisteman (sistema lexikoan) errepresentatzen den maila lexiko edo sakonekoa argi eta garbi bereizten ditu.

Programazioari dagokionez, zeuden bi inplementazioak zoritxarrez libreak ez zirenez, programa berri bat egin behar izan zuten C lengoaia erabilita (PCetan eraginkortasunez exekutatu ahal izateko).[12] Programa hori 2022an martxan zegoen arren, bi inplementazio aurreratuago eskuratu zuten hurrengo hamarkadetan:
- Xerox enpresak lizentziatutakoa garai batean. Lauri Karttunen-ek garatutako programa.
- Foma aplikazioa: Mans Hulden-ek software librean sortutako azken urteotan.[17] Software librearekin posible izan da baliabide urriko hizkuntza askotarako halako prozesadoreak garatzea (2022an 40tik gora ziren).
Ikuspuntu linguistikotik interesgarriena eta zailena formalismoaren osagaiak ondo definitzea izan zen. Osagai nagusiak bi hauek dira: sistema lexikoa eta erregela morfofonologikoak.[16][12][18][19]
Sistema lexikoa[aldatu | aldatu iturburu kodea]
Sistema lexikoan morfema-multzoa definitzen da, morfemen artean egon daitezkeen kateamenduen arabera sailkapena eginez (morfotaktika edo paradigmak deitzen zaio atal horri). Definitutako azpilexiko horiez gain, lemen eta aurrizki/atzizkien sekuentzia posibleak arautzen dituzten jarraitze-klaseak ere definitzen dira, azpilexiko multzoak direnak.
Morfemak definitzean «bi mailak» definitu behar dira, azaleko forma (zakur, da zein Gasteiz lemak, edo -ri eta -la atzizkiak, esaterako), eta sakoneko forma informazio morfologikoarekin. Horrela -ri atzizkiari dagokion informazioa datibo mugagabea da, eta sakoneko informazioa Ri da. R hori marka bat da (bi motatakoak dira, morfofonema eta hautapen-markak; aipatu den kasuan, morfofonema da), adierazteko bokal ondoren r hori gauzatu behar dela, baina kontsonante ondoren ez. Adibidez, zakur leman azken r letra markatzen da (zakuR esaterako) r gogorra dela adierazteko, eta da formaren kasuan marka bat jartzen da amaieran adierazteko a hori e bihur daitekeela -la eta -n moduko atzizkien aurrean.
- Morfotaktika. Izen eta aditzekin osatu daitezkeen hitzak[1]
-
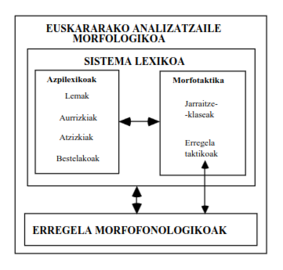 Euskararen morfologiaren analisirako osagaien eskema.
Euskararen morfologiaren analisirako osagaien eskema. -
 Izen arrunten morfotaktika. Zer aurrizki eta atzizkirekin osa dezake hitz bat izen arrunt batek?
Izen arrunten morfotaktika. Zer aurrizki eta atzizkirekin osa dezake hitz bat izen arrunt batek? -
 Aditz nagusien morfotaktika. Zer aurrizki eta atzizkirekin osa dezake hitz bat aditz nagusi batek?
Aditz nagusien morfotaktika. Zer aurrizki eta atzizkirekin osa dezake hitz bat aditz nagusi batek? -
 Morfologia lantzeko kategoria nagusiak.
Morfologia lantzeko kategoria nagusiak.




Erregela morfofonologikoak[aldatu | aldatu iturburu kodea]

Transformazio morfofonologikoen eraginez sakoneko eta azaleko mailen artean sortzen diren diferentziak adierazteko erregelak erabiltzen dira. Erregela horiek automata edo transduktore bihurtzen dira, normalean konpiladore baten bitartez (hasiera hartan eskuz egiten zuten). Konpiladorearen arabera aldatzen dira erregelak idaztean erabiltzen diren sinboloak (espresio erregularretatik gertu, beti), eta r-aren kasuan, adibide sinplifikatu bat emanez, hauexek lirateke aipatutako Foma konpiladorerako erregelak:
- r -> r r || _ «+» Bokal ; # R gogorra bikoizten da bokal aurrean
- Adibidea: zakuR+a -> zakurra
- r -> r || «+» _ Bokal; # R mugagabeko marka r da bokal aurrean
- Adibidea: ume+Ri -> umeri
Garapen hura talde-lana izan zen, lan handia eta emankorra, hainbat argitalpen, batzuk nazioartekoak[14], eta bi tesi sortu baitziren, aipatutako Iñaki Alegriarena[21] eta Miriam Urkiarena.[22] 60.000 sarrera baino gehiago sartu ziren datu-basean (Euskararen Datu-Base Lexikala, EDBL) eta hogeita hamar bat erregela konplexu sortu ziren. Urteetan zehar deskribapena, lexikoa batez ere, aberastuz eta arau berrietara egokituz joan da, eta euskararen prozesaketarako oinarrizko elementua izaten jarraitzen du. Gainera, taldeko hurrengo tesietarako eta aplikazioetarako oinarri garrantzitsua izan zen. Adibidez, Itziar Adurizek, hizkuntzaren aldetik eta Nerea Ezeizak, alde informatikotik, beren tesietan (2000 eta 2002, hurrenez hurren), urrats bat gehiago eman zuten anbiguotasun morfosintaktikoa ebatzi ahal izateko, hitzak analizatu ondoren analisi posibleen artean erabakitzeko (adibidez, zuen hitz forma ea aditz laguntzailea edo izenordaina den erabakitzeko).
Bestalde, aukera izan zuten aholkulari gisa aritu eta, beste hizkuntzetako prozesadore morfologikoetako garapenean laguntzeko, morfologia konplexuko eta baliabide urriko hizkuntzetan batez ere. Zehazki, bi mailatako morfologia edota Foma honako hizkuntza hauetan baliatu dute: kitxua, aimara, guaraniera, nahuatl eta maputxe.
Morfologia konputazionalaren aplikazioak[aldatu | aldatu iturburu kodea]
Analizatzaile morfologiko izenarekin jende gutxik irudikatzen du zenbat aplikazio sor daitezkeen. Baina oinarri horrekin oso tresna interesgarriak gara daitezke, batez ere aukeratutako formalismoarekin, non analisiaz gain sorkuntza ere lor baitaiteke. Asko dira oinarri horretatik egin diren erabilpenak. Hona hemen horietako batzuk:
- Zuzenketa ortografikoa: hitz batek analisia badu zuzentzailearen hiztegiaren parte da, bestela ez (eta azpimarratzen da). Proposamenak sortzeko modulu bat gehitu behar da, eta horretarako sorkuntza morfologikoak laguntzen du.
- OCR (Optical Character recognition, Karaktereen ezagutze optikooa): zuzenketa ortografikoaren parekoa da, baina zuzenketa egiteko karaktereen formarekin lotutako erregelak gehitu behar dira, eta akatsak automatikoki ordezkatzeko aukera.
- Hitzen normalizazioa: testu historikoetan, dialektaletan edo sare sozialetan maiz erabiltzen diren aldaerak identifikatzea eta dagozkien forma estandarrekin lotzea funtsezkoa da halako testuetan.[23] Erregela fonologiko eta lexiko gehigarriekin azkar gara daiteke halako sistema bat.
- Ikasleentzako laguntzak. Jokoak sortzeko, hiztegi-kontsultak errazteko edo ariketak automatikoki sortzeko tresna interesgarria da. Nor-nori-nork taula lantzeko joko bat egitea oso sinplea da, adibidez; edo dagozkion moduko aditz-forma jokatuak hiztegian bilatzen laguntzeko (halakoak, noski, ez baitaude zuzenean hiztegian).
- Itzulpen automatikoan laguntzeko. Ezagutzan oinarritutako ereduan analisi eta sorkuntza morfologikoak ezinbesteko elementuak dira; nahiz eta gaur egungo sistema eraginkorrenetan beste modu batez egiten den.
- Bertsotan ikasteko edo automatikoki osatzeko elementu garrantzitsua da, errima egiaztatzea edo sortzea nahiko erraz gertatzen baita.
Azken bi aplikazioak eta zuzenketa ortografikoarena aztertuko ditugu apur bat sakonago ondoko azpiataletan.
Xuxen[aldatu | aldatu iturburu kodea]

Xuxen zuzentzaile ortografikoa izan zen analizatzaile morfologikoaren lehen aplikazioa, baita arrakastatsuena ere. 1994an sortutako lehen bertsioa, EHUko Ixa taldearen, UZEIren eta Baionako Hizkia enpresaren artean merkaturatua, aparteko programa bat zen, testu-editoreetatik independentea. PC edo Mac batean MS-Word edo WordPerfect-ekin testua editatu eta amaitu ondoren zuzentzea errazten zuen formatu-kontu guztiak errespetatuz. Hasieran garestia zen, eta nagusiki argitaletxeetan eta irakaskuntzan erabili zen. Euskara batua finkatzeko berebiziko tresna izan da. Izan ere, esan daiteke Xuxen laguntza handikoa izan dela azken bi hamarkada hauetan, euskara idatziaren normalizazioan, Euskaltzaindiaren hiztegi-arauak eta gomendioak kaleratu eta gutxira normaltasunez onartuak eta erabiliak izan zitezen.[24] Aplikazio giltzarria da normalizazioaren bidean.
Euskarak duen konplexutasun/aberastasun morfologikoa dela eta, hitz bat ondo dagoen ala ez erabakitzeko ezin zen, beste hizkuntza batzuetarako egiten zen bezala, hitz-zerrenda batean oinarritu; lema batetik abiatuta sor daitezkeen zilegi diren formak asko direnez, zerrenda izugarria izango bailitzateke. Hori dela eta, egindako hurbilpena teknologia aldetik oso berritzailea izan zen, zuzentzaile gehien-gehienak hitzetan oinarritzen baitziren, eta ez morfologian.[25] Esan bezala, analisirik ez zuen edozein hitz susmagarritzat jotzen zuen, eta, ondorioz, azpimarratu egiten zuen. Gainera, bi ezaugarri ahaltsu zituen:
- Proposamenak egiteko ohiko bideez gain (hitzaren karaktere bat gehitzea, aldatzea edo ezabatzea) «ohiko akatsak» hartzen zituen kontuan. Horretarako erregela morfofonologiko eta lexiko-sarrera berriak idatzi ziren. Adibidez, lexikoan haundi lema gehitu zen dagokion handi estandarrarekin lotuta. Erregelei dagokienez, hainbat fenomeno aurreikusten ziren: h-a ez jartzea, x/j aldaketa, o/u nahastea lemaren amaieran, erdararen eraginez v edo c idaztea, esate baterako.
- Erabiltzailearen hiztegia. Hitz-forma berriak gehi zitezkeen, eta, horri esker, aurrerantzean hitz-forma hori ez ezik, haren flexio osoa ezagutuko zen, beste ezer egin gabe. Erabilpen teknikorako oso garrantzitsua den ezaugarria, eta zoritxarrez, 2023ko sistemetan integratzen ez zena.
Arrakastatsua izan arren, ortografia testua amaitu ondoren egiaztatu behar zen, ez baitzegoen integratuta testu-editoreetan, Word eta Word Perfect-eko formatua errespetatzen bazuen ere. Hori dela eta, eskaera handia ze-formatua errespetatzen bazuen ere. Hori dela eta, eskaera handia zegoen integratuta egon zedin ohiko testu-editoreetan, batez ere argitaletxeetan eta administrazioan.
Microsoftekin akordio bat bideratu eta gero, hala gertatu zen; eta hurrengo urteetan, Eleka-Elhuyarrek egindako lanari esker, beste enpresa batzuetako aplikazioetan integratzen joan zen.[26] Software librearen bertsioa ere lortu zen, nahi baino beranduago, morfologikoki konplexu diren hizkuntzetarako zeuden zuzentzaile estandarrak desegokiak zirelako.[9] Hungariatik proposatutako Hunspell estandartzat hartu zenean, berriz, dena erraztu zen. Hizkuntzaren aldetik, osatuz eta eguneratuz joan da, eta zuzentzaile ortografiko berriak sortu dira euskararako: Hobelex (UZEIk kaleratua eta ezagutza berean oinarritua) edo multinazionalek gaur egun, zorionez, eskaintzen dituztenak (Microsoftena dagoeneko ez da Xuxen, eta Google Docs-ek berea du).
Bizkaierarako ere bertsio bat egin zen Ixa eta Eleka-Elhuyarren batera, Labayrurekin lankidetzan.[27] Datu-basean forma berriak sartu ziren lehenetsitako estandarrekin lotuta (deutso-dio, uri-hiri, gitxi-gutxi...) eta hautazko erregela morfofonologiko berriak gehitu ziren morfemetan eta azalean aldaketak eragiteko (-sino ->sio, -e->-a, -ea->-a, esate baterako, telebisino/telebisio, laba/labe eta alabea/alaba onartu eta proposatu ahal izateko). Arrakasta mugatua izan da, bizkaiera estandarizatua» ez dagoelako ondo definituta, besteak beste.
Beste aplikazioak: itzulpen automatikoa eta bertsolaritza[aldatu | aldatu iturburu kodea]
Morfologia funtsezko osagaia da itzulpen automatikoan ere, ezagutzan oinarritutako teknologian erabiltzen denean. Batez ere. gaztelania-euskara (es-eu) bikoterako garatu zuten Matxin itzultzailean. Prozesadore morfologikoa berrerabili zuten, baina analisiari baino gehiago sorkuntzari atera zioten etekina.[28][29]
Gaur egun, itzulpen automatikoan emaitza onenak sistema neuronalekin lortzen dira, baina horretarako testu-masa handiak behar dira. Egoera horretan ez dauden hizkuntzen kasuetan, ezagutzan oinarritutako hurbilpena erabiltzen da oraindik.
Bertsolaritzari dagokionez, prozesadore morfologikoak erraztu zuen bertsogintzako hainbat ataletan errima egiaztatzea eta hitz errimatuak sortzea, batez ere, eta neurria kontrolatzea.[30]
Lehen urrats batean,[31] hitz errimatuak egindako inplementazioa erabiliz sortzea izan zen helburua, hitzak eta morfema-sistema osoa atzekoz aurrera bihurtu zituzten, horrela posible eginez sorkuntza abiatzea amaieratik hasita.

Bigarren urrats batean,[32] aurreko elementua asko sinplifikatu zuten, garaiko teknologiak ahalbidetzen zuelako konpilazio automatikoan reverse eragilea erabiltzea. Gero, eta teknologia berarekin silaba-banatzaile edo -kontatzaile batekin osatuta, bertso-bilketa bat egin zen eta bertso-eskoletako ikasleei begirako aplikazio bat garatu zen (arbel digitala). Eta azkenik, Bertsobot izeneko proiektuari hasiera eman zioten, non epe luzeko helburua zen adimen artifizialeko erronka handi bati ekitea: bertso-sorkuntza.
2012rako eginak zeuden hurbilpen oinarrizkoenak: 1) Memoria hutseko lana, 2) Corpusen gaineko bilaketa arrunta, eta 3) Corpusen gaineko bilaketa adimenduna. Horrez gain, sorkuntza librean urrats batzuk eman ziren.
Hortik aurrera, Bertsobotek garapen interesgarria izan du EHUko beste talde bitan: robotikan[33] eta kantaeraren sorkuntzan Sarasola.[34] Aurrerapen horiekin guztiekin, eta adimen artifizialean testu-sorkuntzan gertatzen ari diren aurrerapen izugarriekin ez litzateke harritzekoa laster Bertsobot errealitatea izatea.[35][36]
Ikergaiak. Morfologia testuetatik inferitzea[aldatu | aldatu iturburu kodea]
Aipatutako Koskenniemmiren eta Karttunenen ekarpenetatik abiatuta egoera finituko morfologia asko garatu zen, eta horrek euskarari eta morfologikoki konplexu diren beste hizkuntza askori lagundu zien irtenbide konputazionala bideratzen. Ildo horretatik, Karttunen-entzat 2007an morfologia konputazionala guztiz bideratuta zegoela, zientzia aldetik problema ebatzia zela («from a computational point of view morphology was a solved problem»).[37]
Hizkuntza semitikoen morfologiarako ere irtenbidea aurkitu zen bi mailako ereduari mailak gehituz. Baina, zer gertatzen da hizkuntza baten lexikoa eta arau morfologikoak ezezagunak direnean? Edo, ezagutu arren, garapen konputazional azkar bat egin nahi dugunean? Hor aukera interesgarria da zuzenean testuetatik morfologia inferitzea. Funtsezko ikergaia bihurtu da hori XXI. mendean, bi urratsetatik igaroz: eredu estatistikoa eta ikasketa sakona.[2]
Morfologia inferitzeko eredu estatistikoa[aldatu | aldatu iturburu kodea]
Testu hutsetatik abiatuta hitzak osatzen dituzten morfemak inferitzea proposatu da. Metodoen oinarria testuetako hitzen hasierak eta, batez ere, amaierak estatistikoki aztertzean datza, aurrizkiak, artizkiak eta atzizkiak identifikatuz, eta bide batez stem-ak (azaleko lemak edo sasi-lemak). Azaleko mailan lan egiten duten metodo hauek, beraz, forma kanonikoen ordez hitz-zatiak identifikatzen dituzte, aldaketa morfofonologikoak kontuan hartu gabe (horregatik lemak baino stem-ak identifikatzen dira).[2]
Arrakasta handienetako metodoen artean Morfessor aipa daiteke, flexio handiko hizkuntzetarako egokia delako. Ixa taldeko Izaskun Etxeberriaren tesian tresnaren funtsa azaltzen da eta euskararen testu historikoei aplikatzen zaie (garaiko osagai morfologikoak identifikatu nahian). Etxeberriak zioenez:[38]
- "...tresnaren helburua da hizkuntza-eredu bat induzitzea modu ez-gainbegiratuan testu hutseko corpus batetik abiatuta. Oinarrizko hizkuntza-eredua (Baseline model deitzen diote) morfemaz osatutako lexikoi bat da (M), beraz, helburua da lexikoi onena bilatzea sarrerako corpusa segmentatzeko."
Eta adibideak ere ematen zituen:
- "Horrela lortu ditugu, esaterako, amoreakgatik → amore + ak + gatik
- edota elkharri → elkhar + ri moduko segmentazioak..."
Itzulpen automatiko neuronalean oso hedatua dagoen BPE metodoa[39] ere saiatzen da atzizki adierazgarriak lortzen hitz ezezagunetan, eta bide batez hitz horiei dagozkien lemak asmatzen. Euskararako ere erabili izan da eta emaitza onak ematen ditu.[2]
Baina Etxeberriaren tesian helburu nagusia testu historikoen normalizazioa da, eta horretarako forma historiko bakoitza gaur egungo idazkeran dagokion forma estandarrekin lotzen da, testu historikoen kontsulta errazteko asmoz.[40] Hori lortzeko, erregela morfofonologikoak inferitzen dira, baina ezagutzan oinarritutakoetan ez bezala sortzen diren transduktoreak eredu probabilistiko batean konbinatzen dira. Horrela, amoreakgatik lotzen da amoreengatik forma estandarrarekin eta elkharri, elkarri formarekin, eta horretarako ak/en aldaketa ikasten da, baita h-ren galera ere zenbait testuingurutan. Tesian frogatzen da helburu horretarako ezagutzan oinarritutako erregeletan baino emaitza hobeak lortzen direla eredu estatistikoekin, betiere eskuz prestatutako bikote (aldaera/estandarra) zerrenda batetik abiatuta.[2]
Teknika estatistiko horiek testu historikoak edo dialektalak prozesatzeko asko erabiltzen dira, baita OCR (Optical Character Recognition, Karaktereen ezagutze optikoa) akatsak zuzentzeko edo sare sozialetako testuak normalizatzeko ere.[2]
Morfologiaren inferentzia ikasketa sakonaren bidez[aldatu | aldatu iturburu kodea]
Aipatu den bezala, azken urteotan morfologia konputazionalaren ikerkuntzan lerro nagusia morfologia inferitzea izan da, hau da, adibideetatik paradigmak eta aldaera fonologikoak orokortzea, salbuespenak ere bereiziz. Horretarako bide emankorrenetako bat shared task edo partekatutako atazak izan dira. Horietan erronka bat planteatzen da modu irekian, eta mundu osoko edozein ikertzaile edo ikertzaile taldek parte har dezake soluzio onena bilatzen. Horrelako erronketan ohikoak izaten dira ikasketa sakonean oinarritutako sistemak, eta morfologia konputazionala ez da salbuespena izan.[2]
Horren adibidea SIGMOrPHON ataza partekatua da. Hasieran helburua datuetatik abiatuta sortzaile morfologikoak garatzea izan zen eta aurrerago bestelako atazak gehitu zituzten. Morfologiara aplikatutako ikasketa sakonaren gorakada nagusia LMU-MED[41] sistemarekin hasi zen, 2016an,[42] non Kann-en sistema hoberena izan zen beste guztiekin alderatuta, eta sistema neuronalen egokitasuna agerian geratu zen ataza honetarako. Hurrengo urteetan ataza partekatuetan erabili ziren sistema gehienek modu batean edo beste batean ikasketa sakoneko ereduren bat erabili dute, dela LSTMdun sare errekurrenteak edo gaur egun puri-purian dauden transformer ereduak. Ataza horietan frogatuta geratu da datu nahikoa eskura izanez gero, sortzaile morfologikoak sortzea erlatiboki erraza dela.[2]
Azken urteotan, baina, interesa piztu dute datu gutxirekin sortutako sistemek eta honako galderei erantzuten saiatu dira: zenbat aditz jokatu behar ditugu aditzetarako sortzaile morfologiko bat sortzeko? Horrelako galderak planteatu zituzten 2018ko sorkuntza morfologikoko ataza partekatuan, non 100 hizkuntzatarako sortzaile morfologikoak sortzea zen ataza. Datu gutxi zuten hizkuntzetan enfasia egitearren, hiru modalitatetan lan egiteko aukera eskaini zuten: txikia, ertaina eta handia; entrenamendurako, berriz, 100, 1.000 edo 10.000 datu-instantzia ematen ziren. Gai hauetan egiten diren aurrerapenak baliabide urriko hizkuntzetarako baliagarriak izan daitezke.[2]
100 hizkuntza horien artean euskara zegoen eta sistema onenak, % 98,90ko asmatze-tasa izan zuen datu-multzo handienarekin, % 88,10ekoa datu-multzo ertainarekin eta % 13,30ekoa txikienarekin.[2]
Orokorrean, urtez urte emaitzak hobetuz badoaz ere, badaude oraindik mugak. Egoera finituko makinetan (FSM) oinarritutako sistemak oso eraginkorrak dira, teorikoki modu oso konpaktuan sistema oso konplexuak kodetzen baitituzte. Gainera, jakintza linguistikoa eskuz kodetuta dagoenez, arazo bat baldin badago, nahiko erraza da arazoaren muina aurkitu eta konpontzea. Sistema neuronalen arazo bat, berriz, gaur egun puri-purian dagoena, irakurgarritasun edo interpretabilitatea da. Sare neuronaletan oinarritutako sistema guztiek sarrerako edozein datu emanik emaitza bat itzultzen dute, eta askotan irteera hori nola eta zergatik itzuli duten interpretatzea ez da erraza. Horregatik, maiz sare neuronalok kutxa beltzak direla esan ohi da.[2]
Bestalde, ematen du ikasketa sakoneko hurbilpenean, oro har, informazio linguistikoak ez duela toki handirik eta, corpus erraldoiak izanez gero, emaitza ona itzultzen duela, askotan, informazio linguistikoa erabiliko bagenu baino hobea, itzulpen automatikoko hainbat kasutan ikusi izan dugun bezala. Hala ere, badira ahotsak itsu-itsuan ibiltze horrekin oso ados ez, eta informazio linguistikoa oinarrian erabilita sistema neuronalak martxan jarri dituztenak, emaitzak hobetuz morfologian.[43][2]
Erreferentziak[aldatu | aldatu iturburu kodea]
Artikuluaren testua neurri handi batean CC-BY-SA lizentzia duen liburu-kapitulu honetatik atera da: "Aduriz, Itziar; Agirrezabal, Manex; Agirre, Eneko; Alegria, Iñaki; Arregi, Xabier; Arriola, Jose Mari; Artola, Xabier; Diaz de Ilarraza, Arantza; Estarrona, Ainara; Etxeberria, Izaskun; Ezeiza, Nerea; Sarasola, Kepa. (2023). «Morfologia Konputazionala Euskaraz, 35 urte» Miren Azkarateri esker onez (UPV/EHU Argitalpen Zerbitzua): 15–30. ISBN 978-84-1319-536-0.
- ↑ a b c d Urkia Gonzalez, Miriam; Alegria Loinaz, Iñaki. (2002). Morfologia konputazionala. UEU ISBN 978-84-8438-034-4. (Noiz kontsultatua: 2023-09-05).
- ↑ a b c d e f g h i j k l m Aduriz, Itziar; Agirrezabal, Manex; Agirre, Eneko; Alegria, Iñaki; Arregi, Xabier; Arriola, Jose Mari; Artola, Xabier; Diaz de Ilarraza, Arantza; Estarrona, Ainara; Etxeberria, Izaskun; Ezeiza, Nerea; Sarasola, Kepa. (2023). «Morfologia Konputazionala Euskaraz, 35 urte» Miren Azkarateri esker onez (UPV/EHU Argitalpen Zerbitzua): 15–30. ISBN 978-84-1319-536-0. (Noiz kontsultatua: 2023-08-20).
- ↑ «Morfologia konputazionala [Sareko Euskal Gramatika»] www.ehu.eus (Noiz kontsultatua: 2023-08-25).
- ↑ Xuxen, Kimmo Koskeniemmi eta FSMLNP2012 – Hizkuntza-teknologiak, Ixa Taldearen bloga. 2012-11-04 (Noiz kontsultatua: 2023-08-25).
- ↑ Atro Voutilainen-en hitzaldia. Zuhaitz-bankua finlandierarako.(2011/06/08) – Hizkuntza-teknologiak, Ixa Taldearen bloga. (Noiz kontsultatua: 2023-08-25).
- ↑ eu-spell: Xuxen software libre gisa eskainia eta software librean integratua – Hizkuntza-teknologiak, Ixa Taldearen bloga. 2006-12-07 (Noiz kontsultatua: 2023-08-25).
- ↑ Aranzabe, Maxux; Sarasola, Kepa. (2009-04-29). «Morfologia eta sintaxiko ariketak konputagailuar (udaberriko ikastaroak)» ixa.ehu.eus (Udako Euskal Unibertsitatea) (Noiz kontsultatua: 2023-03-07).
- ↑ Morfologia eta sintaxiko ariketak Internet bidez – Hizkuntza-teknologiak, Ixa Taldearen bloga. (Noiz kontsultatua: 2023-03-07).
- ↑ a b Loinaz, Iñaki Alegría; Zubillaga, Xabier Artola; Sánchez, Arantza Díaz de Ilarraza; Gabiola, Kepa Mirena Sarasola; Aduriz, Itziar; Loinaz, Iñaki Alegría; Zubillaga, Xabier Artola; Sánchez, Arantza Díaz de Ilarraza et al.. (2011). «Teknologia garatzeko estrategiak baliabide urriko hizkuntzetarako» Linguamática 3 (1): 13–31. ISSN 1647-0818. (Noiz kontsultatua: 2023-08-20).
- ↑ «3. Morfologia lexikoa: sarrera - Euskararen Gramatika» www.euskaltzaindia.eus (Noiz kontsultatua: 2023-08-20).
- ↑ (Ingelesez) Manterola, Julen. (2008-05-14). Is Basque an agglutinative language?. (Noiz kontsultatua: 2023-08-20).
- ↑ a b c d Alegría Loinaz, Iñaki. (1995). Euskal morfologiaren tratamendu automatikorako tresnak. Universidad del País Vasco - Euskal Herriko Unibertsitatea, 70 or. (Noiz kontsultatua: 2023-08-20).
- ↑ Agirre, E.; Alegria, I; Arregi, X; Artola, X; Diaz de Ilarraza, A; Maritxalar, M; Sarasola, K; Urkia, M. (1992-03). «XUXEN: A Spelling Checker/Corrector for Basque Based on Two-Level Morphology» Third Conference on Applied Natural Language Processing (Association for Computational Linguistics): 119–125. doi:. (Noiz kontsultatua: 2023-08-20).
- ↑ a b Alegria, I.; Artola, X.; Sarasola, K.; Urkia, M.; Alegria, I.; Artola, X.; Sarasola, K.; Urkia, M.. (1996). «Automatic morphological analysis of Basque» Literary and Linguistic Computing 11 (4): 193–203. doi:. ISSN 1477-4615. (Noiz kontsultatua: 2023-08-20).
- ↑ Roteta, Izaskun Aldezabal; Gabiola, Kepa Sarasola; Egurrola, Jose Mari Arriola; Sanchez, Arantza Diaz de Ilarraza. (2005-07-19). Hizkuntzalaritza konputazionala. UEU ISBN 978-84-8438-065-8. (Noiz kontsultatua: 2023-08-25).
- ↑ a b Eneko Agirre, Iñaki Alegria, Xabier Arregi, Xabier Artola, Arantza Diaz de Ilarraza, Montse Maritxalar, Kepa Sarasola, Miriam Urkia, A. Agirre, P. Goenaga. (1991). «BI MAILATAKO MORFOLOGIAREN EUSKARARAKO EGOKITZAPENA» 1library.co (Noiz kontsultatua: 2023-08-20).
- ↑ (Ingelesez) Alegria, Iñaki; Etxeberria, Izaskun; Hulden, Mans; Maritxalar, Montserrat. (2010). Yli-Jyrä, Anssi ed. «Porting Basque Morphological Grammars to foma, an Open-Source Tool» Finite-State Methods and Natural Language Processing (Springer): 105–113. doi:. ISBN 978-3-642-14684-8. (Noiz kontsultatua: 2023-08-20).
- ↑ Urkia, Miriam. (1997). «Euskal morfologiaren tratamendu informatikorantz | Ixa taldea» www.ixa.eus (Noiz kontsultatua: 2023-08-20).
- ↑ Iñaki Alegria, Miriam Urkia. (2002). «Morfologia Konputazionala. Euskararen morfologiaren deskribapena. | Ixa taldea» ixa.si.ehu.es (Noiz kontsultatua: 2023-08-20).
- ↑ Fernandez, Luistxo. (1995-12-24). «Baina euskaraz ari banaiz...» Euskaldunon Egunkariaren hemeroteka. 1990-2003. (berria,eus) (Noiz kontsultatua: 2023-08-20).
- ↑ Alegria Loinaz, Iñaki. (1994). Euskal morfologiaren tratamendu automatikorako tresnak. UPV/EHU (Noiz kontsultatua: 2023-09-02).
- ↑ Urkia Gonzalez, Miriam. (1997). Euskal morfologiaren tratamendu informatikorantz. UPV/EHU ISBN 978-84-8438-579-0. (Noiz kontsultatua: 2023-09-02).
- ↑ Etxeberria Uztarroz, Izaskun. (2016). Aldaera linguistikoen normalizazioa inferentzia fonologikoa eta morfologikoa erabiliz. Universidad del País Vasco - Euskal Herriko Unibertsitatea (Noiz kontsultatua: 2023-08-24).
- ↑ Aduriz, Itziar; Alegría Loinaz, Iñaki; Artola Zubillaga, Xabier; Sarasola, Koldo. (2021). «Euskara (batua) ingurune digitalean: bidean ikasixa eta etorkizuneko erronkak» Arantzazutik mundu zabalera: euskararen normatibizazioa, 1968-2018 = la normativización del euskera, 1968-2018 = la standarisation de la langue basque, 1968-2018 = Basque language's standardization, 1968-2018, 2021, ISBN 978-84-9192-213-1, págs. 455-470 (Euskaltzaindia): 455–470. ISBN 978-84-9192-213-1. (Noiz kontsultatua: 2023-08-24).
- ↑ Aduriz, I.; Urkia, M.; Alegria, I.; Artola, X.; Ezeiza, N.; Sarasola, K.. (1997-04-01). «A spelling corrector for Basque based on morphology» Literary and Linguistic Computing 12 (1): 31–38. doi:. ISSN 0268-1145. (Noiz kontsultatua: 2023-08-24).
- ↑ «Xuxen.eus - Xuxen - Bertsio nagusiak deskargatu» xuxen.eus (Noiz kontsultatua: 2023-08-24).
- ↑ Alegria, I.; Aranbarri, G.; Ceberio, K.; Labaka, G.; Laskurain, B.; Urizar, R.; Alegria, I.; Aranbarri, G. et al.. (2010). «A morphological processor based on foma for Biscayan (a Basque dialect)» Proceedings of the 7th International Conference on Language Resources and Evaluation, LREC 2010 (European Language Resources Association (ELRA)): 828–831. ISBN 978-2-9517408-6-0. (Noiz kontsultatua: 2023-08-24).
- ↑ Mayor Martinez, Aingeru. (2007). Matxin. Erregeletan oinarritutako itzulpen automatikoko sistema baten eraikuntza estaldura handiko baliabide linguistikoak berrerabiliz (matxin. Construcción de un sistema de traducción automática basado en reglas reutilizando recursos lingüísticos de amplia cobertura). Universidad del País Vasco - Euskal Herriko Unibertsitatea (Noiz kontsultatua: 2023-08-24).
- ↑ Matxin itzultzaileak beste bi urrats egin ditu – Hizkuntza-teknologiak, Ixa Taldearen bloga. (Noiz kontsultatua: 2023-08-25).
- ↑ Tesia: Bertso-neurketa automatikoa (Manex Agirrezabal, 2017-06-19) – Hizkuntza-teknologiak, Ixa Taldearen bloga. (Noiz kontsultatua: 2023-08-25).
- ↑ Arrieta, B.; Alegria, I.; Arregi, X.. (2001). «An Assistant Tool for Verse-Making in Basque Based on Two-Level Morphology» Literary and Linguistic Computing 16 (1): 29–43. doi:. ISSN 1477-4615. (Noiz kontsultatua: 2023-08-24).
- ↑ Agirrezabal, Manex; Alegria, Iñaki; Arrieta, Bertol; Astigarraga, Aitzol. (2012). «BertsoBot : lehen urratsak» bdb.bertsozale.eus (UPV/EHU) (Noiz kontsultatua: 2023-08-24).
- ↑ Astigarraga Pagoaga, Aitzol. (2017). Bertsobot: gizaki-robot arteko komunikazio eta elkarrekintzarako portaerak. Universidad del País Vasco - Euskal Herriko Unibertsitatea (Noiz kontsultatua: 2023-08-24).
- ↑ Sarasola, Xabier. (2020). «Application of singing synthesis techniques to bertsolaritza» aholab.ehu.eus (UPV/EHU) (Noiz kontsultatua: 2023-08-24).
- ↑ «Manex Agirrezabal: "Konputagailuek bertsoak modu naturalean sortzea lortuko dute" — Unibertsitatea.Net» www.unibertsitatea.net (Noiz kontsultatua: 2023-08-25).
- ↑ Bertsoak idazten laguntzeko “Arbel digitala” aurkeztu dute. – Hizkuntza-teknologiak, Ixa Taldearen bloga. (Noiz kontsultatua: 2023-08-25).
- ↑ Karttunen, Lauri. (2007). «Word Play» direct.mit.edu (Computational Linguistics) (Noiz kontsultatua: 2023-09-02).
- ↑ Etxeberria Uztarroz, Izaskun. (2016-07-11). Aldaera linguistikoen normalizazioa inferentzia fonologikoa eta morfologikoa erabiliz. (Noiz kontsultatua: 2023-09-02).
- ↑ Sennrich, Rico; Haddow, Barry; Birch, Alexandra. (2016-08). «Neural Machine Translation of Rare Words with Subword Units» Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Association for Computational Linguistics): 1715–1725. doi:. (Noiz kontsultatua: 2023-09-02).
- ↑ «Introduction | Sintaktikoki etiketatutako euskarazko corpus historikoa» ixa2.si.ehu.eus (Noiz kontsultatua: 2023-09-02).
- ↑ Kann, Katharina; Schütze, Hinrich. (2016-08). «MED: The LMU System for the SIGMORPHON 2016 Shared Task on Morphological Reinflection» Proceedings of the 14th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology (Association for Computational Linguistics): 62–70. doi:. (Noiz kontsultatua: 2023-09-02).
- ↑ Cotterell, Ryan; Kirov, Christo; Sylak-Glassman, John; Yarowsky, David; Eisner, Jason; Hulden, Mans. (2016-08). «The SIGMORPHON 2016 Shared Task—Morphological Reinflection» Proceedings of the 14th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology (Association for Computational Linguistics): 10–22. doi:. (Noiz kontsultatua: 2023-09-02).
- ↑ Nzeyimana, Antoine; Niyongabo Rubungo, Andre. (2022-05). «KinyaBERT: a Morphology-aware Kinyarwanda Language Model» Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (Association for Computational Linguistics): 5347–5363. doi:. (Noiz kontsultatua: 2023-09-02).
Bibliografia[aldatu | aldatu iturburu kodea]
- Euskara Institutua, EHU, "Morfologia konputazionala", Sareko Euskal Gramatika (SEG), www.ehu.eus/seg ISBN: 978-84-693-9891-3
- Gonzalez, Miriam Urkia; Loinaz, Iñaki Alegria. (2002-12-17). Morfologia konputazionala. UEU ISBN 978-84-8438-034-4.
- Alegria Loinaz, Iñaki. (1994). Euskal morfologiaren tratamendu automatikorako tresnak. UPV/EHU
Ikus, gainera[aldatu | aldatu iturburu kodea]
- IXA_pipes
- Hizkuntzaren prozesamendua
- Itzulpengintza automatikoa
- Association for Computational Linguistics (ACL)
- Computational Linguistics aldizkaria
- Eneko Agirre
- Xabier Arregi
- Xabier Artola
- Arantza Diaz de Ilarraza
- Montserrat Maritxalar
- Rodrigo Agerri
Kanpo estekak[aldatu | aldatu iturburu kodea]
- (Ingelesez) Association for Computational Linguistics (ACL)
- (Ingelesez) ACL Anthology of research papers
- (Ingelesez) Language Technology World
- Hizkuntzalaritza konputazionala atala Sareko Euskal Gramatikan (SEG)
- UEUko "Hizkuntzalaritza konputazionala" liburua deskargatu.
- Ixa taldea. EHUko ikerketa taldea.
- HAP masterra. EHU-ko Hizkuntzaren Azterketa eta Prozesamendua masterra.
- Berbatek. Hiru urterako (2009-2011) ikerketa estrategikoko proiektu bat da, eta Elhuyar Fundazioak, EHUko Ixa eta Aholab ikerketa-taldeek eta Vicomtech eta Robotiker teknologia-zentroek osatzen dute proiektu hori gauzatzeko partzuergoa.
- Langune hizkuntzen Industriaren alorreko Euskal Herriko enpresen elkartea da. Elkarte hau 2010an sortu da eta itzulpengintza, edukiak, irakaskuntza eta hizkuntzen teknologiaren alorreko 30 enpresatik gora elkartzen ditu.
| Autoritate kontrola |
|
|---|
 Datuak: Q11937582
Datuak: Q11937582